Go Slices: internals and usage
本文基于官方文档,并借鉴了大量讨论 slice 的文章来综述 slice 的底层结构和使用方法。你可以在文末找到这些文章的链接,欢迎阅读。
介绍
Go 的切片类型提供了一种处理类型化数据序列的便捷高效的方法。切片类似于其他语言中的数组,但具有一些不寻常的属性。
Arrays
切片类型是建立在 Go 数组类型之上的抽象,但它在日常编程中的使用并不多,此处仅作简单介绍。
- 数组类型定义指定长度和元素类型。例如,类型 [4]int 表示一个由四个整数组成的数组。
- 数组的大小是固定的(数组的 len 和 cap 相等,就等于数据长度),它的长度是其类型的一部分([4]int 和 [5]int 是不同的、不兼容的类型)。
- 数组可以以通常的方式索引,因此表达式 s[n] 访问第 n 个元素,从零开始。
- 数组不需要显式初始化;数组的零值是一个随时可用的数组,其元素本身已为零
1 | var sliceA [2]int |
Slices
切片的类型规范为 []T,其中 T 是切片元素的类型。与数组类型不同,切片类型没有指定的长度。切片文字的声明方式与数组文字类似,只是省略了元素计数:
1 | var sliceA []int |
// 注意:slice 只可以和 nil 做比较, slice 之间做比较编译期间就不会通过。
1 | > fmt.Println(sliceA == sliceB) |
数据结构
https://github.com/golang/go/blob/master/src/runtime/slice.go#L15
1 | type slice struct { |
array是指向数组的指针。len是切片中的元素数量(与调用len(s)获得的值相同)。cap是切片的总容量(切片开头和分配内存末尾之间可以容纳的元素数量)。
从 slice 的数据结构来看,它所存储的是数据数组的指针地址(array)。所以如果传递切片,就会创建一个指向原始数组 array 的一个新的 slice 切片。这样,对切片的操作就与对数组索引的操作有着相同的高效性,但这也造成了新切片元素的改动会同时影响到原始切片元素(这是因为 array 是相同的)。
append 元素(扩容机制)
1 | sliceA := []int{1, 2, 3} |
append 的两种场景
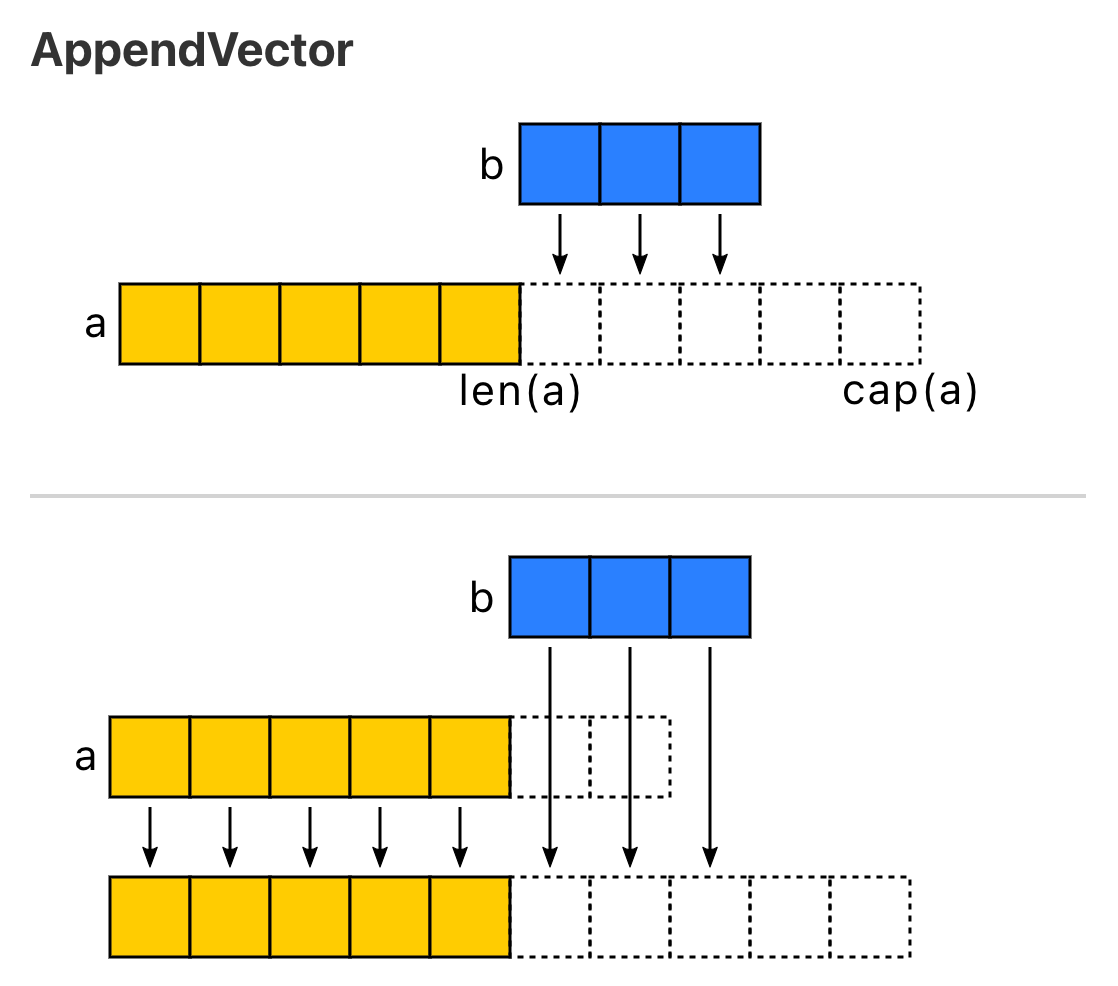
- 当 append 之后的长度小于等于 cap,将会直接利用原底层数组剩余的空间。
- 当 append 后的长度大于 cap 时,则会分配一块更大的区域来容纳新的底层数组。
因此,为了避免内存发生拷贝,如果能够知道最终的切片的大小,预先设置 cap 的值能够获得更好的性能。
growslice 切片扩容
1 | // growslice allocates new backing store for a slice. |
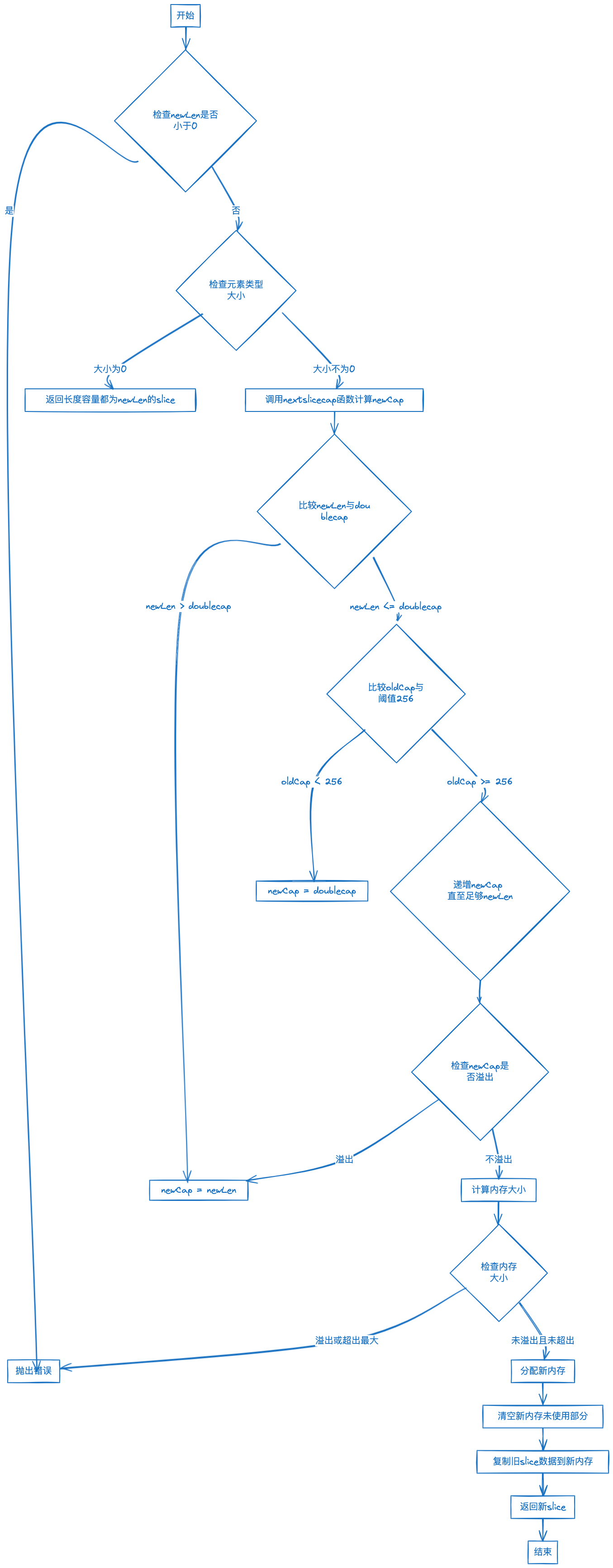
slice 扩容过程的简化流程:
- 检查新长度 newLen 是否超过旧 slice 的容量 oldCap,如果新长度 newLen 小于 0,则抛出错误。
- 如果所处理的元素类型的大小为零,返回长度和容量都和新长度 newLen 相同的 slice。
- 使用 nextslicecap(newLen, oldCap) 函数计算新的容量 newCap:
- 首先,新的容量 newCap 初始化为旧的容量 oldCap 的二倍。
- 如果新长度 newLen 大于这个 doublecap,那么新长度 newLen 就会成为新的容量 newCap。
- 如果旧的 slice 容量 oldCap 小于阈值 256,则新的容量 newCap 就是 doublecap,即旧容量的二倍。
- 如果旧的 slice 容量 oldCap 大于阈值 256,那么新的容量 newCap 就会在旧的容量 oldCap 基础上增长约 25%,在增长过程中,只要新的容量 newCap 足以容纳新长度 newLen,增长过程就会停止。
- 在整个过程中,一旦 newCap 出现溢出,将直接将新长度 newLen 设为新容量 newCap。
- 根据元素类型和新的容量 newCap,计算需要的内存大小,并在特殊情况下(例如元素类型大小为 1、指针大小以及 2 的幂次)做一些优化操作。在这个过程中,可能需要特别处理来避免计算溢出。
- 检查计算结果是否溢出或者超出最大分配大小,如果是则抛出错误。
- 为新的容量 newCap 分配新的内存。
- 清空新内存的未使用部分。
- 将旧 slice 的数据复制到新的内存中。
- 返回新的 slice,包括新内存的指针,新的长度 newLen 和新的容量 newCap。
截取(拷贝)
切片表达式的签名:s[start:end:cap]
基于切片 s 创建一个新的切片(可以包括原切片的所有元素),包含的元素从索引 start 处开始,到但不包括 end 索引处的元素,cap 是新创建子切片的容量,是可选的。如果 cap 省略,子切片的容量等于其长度。子切片的长度计算公式:end - start。
1 | sliceA := []int{1, 2, 3} |
- 切片的截取是创建一个指向原始数组
array的一个新的slice切片。新切片的cap最大不得超过原切片cap(超过则会报错panic: runtime error: slice bounds out of range [::5] with capacity 3)。[:n]时,新切片cap等于原切片cap,[n:]新切片cap等于原切片cap减 n。 - 切片在传递的过程中,会创建一个指向原始数组
array的一个新的slice切片,函数中对切片的修改可能会导致原切片的底层数组发生变化。而一旦切片发生扩容,则会对切片进行深度拷贝,深度拷贝会创建一个新的切片,并拷贝原切片的元素,新切片将拥有自己独立的元素副本。 - 可以使用
func copy(dst, src []T) int函数对切片进行深度拷贝, dst 是目标切片,src 是源切片。两个切片必须有相同的元素类型 T。该函数返回复制的元素数量,取 dst 和 src 长度的最小值。注意,如果目标切片 dst 的长度小于源切片 src 的长度,则只会复制 src 的前 len(dst) 个元素。要深度复制整个切片,必须确保 dst 具有足够的容量以容纳 src 的所有元素。
range 遍历
1 | sliceA := []int{1, 2, 3} |
技巧与陷阱
slice 不是并发安全的数据结构
将切片 slice 作为输入传递给 append 或函数后避免再次使用它
对于初学者或不理解底层原理的用户而言,append 或传递后的 slice 变得不可预测(详见上面的 append 元素(扩容机制))。在日常场景中,避免再次使用可以减少很多奇奇怪怪的问题。
预分配 slice 内存,避免 growslice 发生内存拷贝
1 | sliceA := []int{1, 2, 3} |
切片复用,避免重复创建
1 | func TrimSpace(s []byte) []byte { |
对于性能敏感的场景, 复用对象可以避免反复的对象创建的内存开销。另外还有使用 sync.Pool 以及使用俄罗斯大佬 (fasthttp 作者) 的 bytebufferpool 将性能推到极限的做法(详见: Golang 中预分配 slice 内存对性能的影响(续))。
避免切片内存泄漏
1 | var gopherRegexp = regexp.MustCompile("gopher") |
for i := 0; i < len(slice); i++ { ... } 迭代,避免 range 值拷贝开销
1 | sliceA := []int{1, 2, 3} |
对于性能敏感的场景,避免使用 range 可以减少值拷贝开销。range 在迭代过程中返回的是迭代值的拷贝,如果每次迭代的元素的内存占用很低,那么 for 和 range 的性能几乎是一样,例如 []int。但是如果迭代的元素内存占用较高,例如一个包含很多属性的 struct 结构体,那么 for 的性能将显著地高于 range,有时候甚至会有上千倍的性能差异。对于这种场景,建议使用 for,如果使用 range,建议只迭代下标,通过下标访问迭代值,这种使用方式和 for 就没有区别了。如果想使用 range 同时迭代下标和值,则需要将切片/数组的元素改为指针,才能不影响性能。
推荐阅读
- https://github.com/golang/go/blob/master/src/runtime/slice.go
- Go Slices: usage and internals
- Go Wiki: SliceTricks
- Go Slice Tricks Cheat Sheet
- slices: have Delete and others clear the tail #63393
- Does Go’s range Copy a Slice Before Iterating Over It?
- Much Ado About Nil Things: More Go Pitfalls
- They’re called Slices because they have Sharp Edges: Even More Go Pitfalls
- Golang 中预分配 slice 内存对性能的影响
- Golang 中预分配 slice 内存对性能的影响(续)
- 深入探究 Go 中的 array 与 slice
- 你真的了解 go 语言中的切片吗?
- Go 语言高级编程(数组、字符串和切片)
- Go 语言设计与实现(切片)
- Go 语言高性能编程(切片性能及陷阱)
- Go 语言高性能编程(for 和 range 的性能比较)
- Go 扒一扒 sort 工具包底层用的哪些排序算法?
- Slices Package: Binary Search
- Slices Package: Clip, Clone, and Compact
- Slices Package: Compare
- Slices Package: Contains, Delete, and Equal
More to come… :)